Static Typing in Python
Recently I’ve been looking to refresh my python toolchain and switched to using uv and ruff. These are developed by astral, they’ve been easy to adopt, a joy to use and have made my developer experience both easier and better.
Another tool they’re developing is a static typechecker called ty and this made me wonder, should I be typechecking my own code? I’ve always actually really enjoyed writing dynamic python and been on the fence about adding type hints to my code for a while.
I don’t like the look of type annotations, and my main reason to avoid them, is they add so much visual noise, an extra cognitive overhead I don’t really need.
I understand its merits on big shared code bases where resources are plentiful and downtime has to be minimized, but
If I’m developing something by myself, is there really any benefit documenting all my function inputs and return types?
All this is fresh in my head.
And if the tests pass and the code runs fine, why would I need a type checker?
The case against static typing
It’s easy to find proponents for type checking around the internet and they’re quite vocal. It’s much harder to come across someone advocating for dynamic typing.
I was hoping to find someone that could give me a definitive reason NOT to adopt it, that meant I could just stop worrying about it and continue dynamically typing everything.
DHH had this hot take on Lex’ podcast.
DHH: I hate TypeScript
His stance resonates with me. He’s talking about TypeScript, but a lot still applies to typing in python. Although I do use an IDE, coming from a vim background, I hardly rely on its auto-complete or introspection features either.
And for the typed code I’ve come across, I did not perceive any of the benefits and felt I had to contend with all of the ceremony and gymnastics around it.
However he also points out this is just his own opinion and clearly static typing works for lots of other people.
Could it still benefit me?
In the absence of a more conclusive answer, I decided to try it out for myself, on a couple of smaller projects.
I would keep an open mind, fully commiting to seeing the benefits, but in all honesty I was hoping to discover there is indeed zero reason for me to adopt this any further.
Running the typechecker was easy
uv run ty check .The type annotations, on these simple projects, were quite basic, and although I still did not enjoy their look, I could notice some benefits during refactors.
After I got used to the workflow, I decided to try it out on a larger project with an established codebase. The initial type check threw over 200+ type errors and warnings.
Type Annotations from Hell
As I worked my way through some simple deprecation warnings, I ran into more involved issues with my data access layer.
Here is a simplified example of a find function that returns items in my database.
def find(entity, filters=None): """Finds entities in db.""" ...
## e.g. we can use the `find` function to find users## in our database that have both a cat and a dog:query_filters = [ ('has_cat', 'is', True), ('has_dog', 'is', True)]pet_lovers = find('User', filters=query_filters)In the untyped example above the filters field is left undocumented.
We can document them with expected type annotations, but you can see below how much extra visual noise it generates. I’m not a big fan.
def find( entity: str, filters: List[Tuple[str, str, Any]] | None = None) -> Dict[str, Any]: """Finds entities in db.""" ...However as I ran the typechecker across the entirety of my code base, it actually uncovered an exotic and definitely undocumented filter format. A format that worked perfectly fine and something I had fully implemented, but did not match my naive type hint.
Who was it again, that said they had their entire codebase fresh in their head?
Apparently, at some point, I had implemented an or feature on the filter input. The usecase for this was much less common and thus had never spent time documenting any of it.
## by using the `or` filter we can find## users that own EITHER a cat OR a dogquery_filter = {'or': [ ('has_cat', 'is', True), ('has_dog', 'is', True)]}pet_owners = find('User', filters=[query_filter])Although this was a clear win towards typechecking, now I would need to satisfy the typechecker, by adding an even more verbose type annotation..
## so our filters would need to accept a list of eitherTuple[str, str, Any]## OR:Dict[str, List[ Tuple[str, str, Any ]]]Adding it, makes the function signature look like this…
def find( entity: str, filters: List[ Tuple[str, str, Any] | Dict [str, List[Tuple[str, str, Any]]]] | None = None) -> List[Dict]: """Finds entities in db.""" ...This is one of those type annotations from hell, one that’s so hard to parse. This can’t be a real way to write code, can it?
Type Alias
Fortunately I learned that I could use a TypeAlias. As the name implies, they let you wrap the type annotations into a more readable alias.
So the filter statement becomes:
QueryFilter: TypeAlias = Tuple[str, str, Any] ## <-- type gymnastics here
def find( entity: str, filters: List[QueryFilter] | None = None ## <-- readable alias here) -> List[Dict]: """Finds entities in db.""" ...Now to satisfy the type checker (and more importantly actually document the or filter format), we can create a new alias, and combine it with the previous QueryFilter like so:
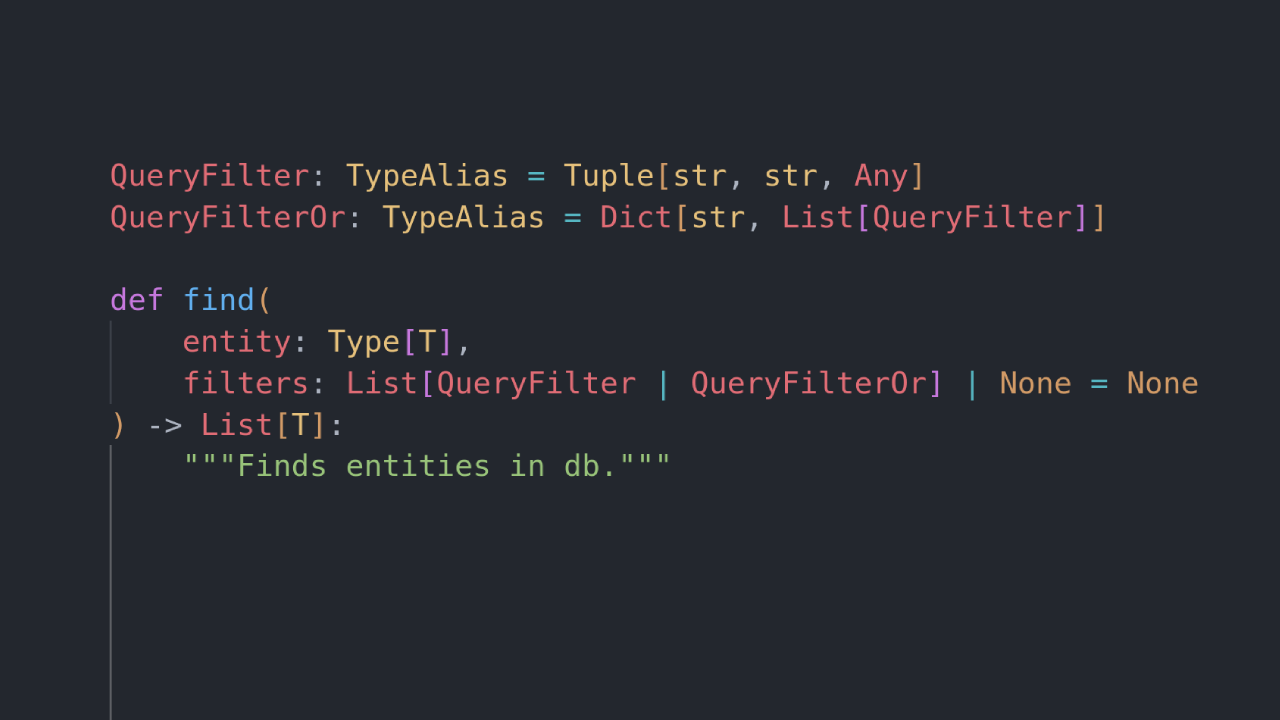
QueryFilter: TypeAlias = Tuple[str, str, Any]QueryFilterOr: TypeAlias = Dict[str, List[QueryFilter]]
def find( entity: str, filters: List[QueryFilter | QueryFilterOr] | None = None) -> List[Dict]: """Finds entities in db.""" ...This is the way!
All of the clarity and with (almost) none of the clutter.
I retain the ability to glance at the function signature and get a quick read on the inputs. But if I want more clarity, I can easily jump up to the TypeAlias to see its precise input type.
I could be on board with this.
The cast that does not cast
For the fun of it, I wanted to make my types even more explicit and wondered if I could somehow reuse the models in my database schema as an interface for the return data on my find functions.
I asked cursor if there was a way I could cast my values using this interface. Apparently I could add Mapped type annotations to my schema models, and then use them to cast my data directly into the expected shape of that model.
Better yet, by casting my data, my IDE + typechecker now allowed me to simplify my code by replacing the ugly dict .get() statements everywhere, for a much more expressive and readable dot notation.
from db.schema.models import User
## Grab a userfound = find_one('User')person = cast(User, found)
if person.get('has_cat'): ## <-- untyped dict get print('They HAVE a cat!')
if person.has_cat: ## <-- simplified typed dot notation print('They HAVE a cat!')This looked so much better!
Unaware however all of this was wrong. I had become overly reliant on the IDE + typechecker, both agreed this was working code, but when I ran it, the python interpreter threw an error:
if person.has_cat ^^^^^^^^^^^^^^AttributeError: 'dict' object has no attribute 'has_cat'The cast function only serves the IDE + typechecker and has zero influence on the runtime code. So for the python interpreter the var person is still just a simple dict without any accessible attributes.
Fine, maybe cast1 was not the best solution, but I still liked the readability of the dot notation.
Dataclasses
To get dot notation, my data would have to become an object somehow. This is what dataclasses are for, and I could use it to actually cast / instantiate my data into the shape, as I originally intended.
from dataclasses import dataclass
@dataclassclass User: id: int name: str has_cat: bool
## Grab a userfound = find_one('User')user = User(**found) ## <-- instead of cast, use a dataclass
if person.has_cat: ## <-- dot notation during typecheck AND runtime print('They HAVE a cat!')This works, but shadowing a schema model with a matching data class, doesn’t seem very dry.
Turns out schema models can be directly instantiated as objects.
from db.schema.models import User
## Grab a userfound = find_one('User')person = User(**found)
if person.has_cat: print('They HAVE a cat!')Much better, we can remove the extra dataclass but retain the dot notation.
Generics and TypeVars
Not bad so far, but now this line was staring me down.
person = User(**found)It means, I’d need to add this line, every time I do a database lookup. If at all possible, I would like to avoid it.
Ideally, instead of returning a dictionary, the lookup functions would return the correct data type automatically, by themselves. However they would still need to be flexible enough to lookup and return any entity in the database.
To implement this we can move the model instantiation into the lookup function. At the function call, instead of passing a string:
found = find_one('User')we’ll pass in the User model as the entity arg
from db.schema.models import User
found = find_one(User)Then within the lookup function, instead of returning a dictionary:
row = cursor.fetchone()return dict(row)We can use the passed in entity class, to instantiate and return it:
row = cursor.fetchone()return entity(**dict(row))Now that the implementation is correct, let’s update the type annotation in the function signature.
Originally it expected an incoming str and returned a Dict
def find_one( entity: str, ## <-- string in filters: List[QueryFilter | QueryFilterOr] | None = None) -> Dict: ## <-- dict out """Finds one entity in db.""" ...But now we need to somehow generalize the type annotations, we need to tell the typechecker that ‘the type that comes in, is the type that comes out’
For this, we can use type variables to define our lookup as a generic function. “These are functions where the types of the arguments or return value have some relationship” as per the documentation
So we can instantiate a type variable as T, then use it to annotate the input and output relationship.
from typing import Type, TypeVarfrom db.schema.models import Base
T = TypeVar('T', bound=Base)
def find_one( entity: Type[T], ## <--- schema model in (class) filters: List[QueryFilter | QueryFilterOr] | None = None) -> T: ## <---------------- schema model out (instance) """Finds one entity in db.""" ...The distinction between the input Type[T] and the output T is that wrapping the type variable in a Type[] means the typechecker expects a class, whereas the naked T type variable signifies a direct instance of T.
Finally I can update my function call and remove that extra line.
from db.schema.models import User
## Grab a userperson = find_one(User)
if person.has_cat: print('They HAVE a cat!')This is what I like, and it satisfies both the typechecker and the runtime. Best of all though, it satisfies my own need for code that is easy to read.
Static vs Runtime
At this point I could see the benefits, but the run-in with the cast function made me aware of something. By adding static type checks, I’m actually splitting the code into two different realities.
There’s the static reality where my IDE and typechecker are trying to catch bugs early, and the dynamic runtime reality that doesn’t adhere to any of the typing functions.
However, since I did not fully appreciate this distinction, I had let myself get lured into a false sense of security when all my static type checks passed.
It reminded me of a comment on a C# reddit thread Why do static type languages feel better than dynamic ones?
“I prefer compile time problems as opposed to runtime problems.” — LeCrushinator (reddit)
In a compiled language like C# this would never happen, as there’s just one reality to adhere to, the compiler’s reality.
And it’s a mistake to assume that, by adding all these type annotations and typechecks to python, they are somehow equivalent to the compile step in other languages. Nothing is further from the truth really.
The type hints in python are fully optional and, as Guido points out, they can contain lies in them2, without it ever affecting the runtime reality of your code.
So in order to get a true sense of security, you still need to run the typechecks in combination with runtime tests.
Conclusion
So where does that leave me, what are the benefits of static type checking, when working on my own projects? Remember, I was hesitant to introduce visual noise, worried that it would add a congitive overhead while working with my own code.
After getting used to the syntax and applying it in earnest on smaller to bigger projects, I found the opposite to be true, actually. I noticed that by adding types it lowered my overall cognitive load. Some areas where I’ve found this to be true and see most of the benefits:
Documentation:
Working by yourself, it’s likely that documenting functions takes a backseat to developing features and bugfixes.
It’s easy to assume all your code is “fresh in my head!”, but as I noticed with the or filter, this format remained fully hidden to myself, while the typechecker simply re-surfaced it for me.
The typechecker can serve as a bulwark against your own laziness.
By adopting type hints, the typechecker keeps complaining until you’ve fully documented the entire function signature. Although annoying at first, once all the inputs are documented, it’s much easier to just relief yourself from all this cognitive load
Refactoring:
Similarly, once all function inputs are documented and accessible to the typechecker, it makes refactors way easier.
By not having to keep all that information in my head, I can now just focus locally on the refactor and let the typechecker go on a wild goose hunt around my codebase. I’m actually surprised by how much more pleasant it makes refactoring.
Reasoning:
Additionally, the act of typechecking lets me reason about my code from a completely different perspective.
In my case it made me wonder “why is the return type of my database lookup function so broadly non-descript”, it led me to refactor my code to more precise return types and ultimately made my code more readable and dare I say elegant?
Final thoughts
Will I still be writing dynamic code?
Currently I’m in the honey moon phase of typing, and still have lots to learn, so will stick with it for a while. Even on the smaller projects I can sense benefits.
However I did not plan for this post to become yet another dogmatic opinion on the internet advocating for one or the other camp. Both typed and dynamic python have their benefits.
Maybe this comment on youtube by pumpichank puts it best:
“For me, Python strikes exactly the right balance with typing, and I was not a fan when it was first introduced because I did’t want Python to become C++ or Java. Typing is never perfect, but because Python’s type annotations are completely optional, I can adopt it when typing is helpful and ignore it when it gets in the way or when the project is too early to bake them in. Type annotations can be an excellent documentation tool in many environments, and definitely help with scaling, but when I just want to duck type some APIs, or just throw together some scripts, it’s perfectly acceptable to omit type annotations. More and more use cases for runtime typing are also being developed, and those are very interesting too.”
Footnotes
-
I feel that cast is a bit of a misleading name for this function. Most programmers would interpret ‘casting data’ to actually transform that data into the shape of the cast. Yet here, the cast only applies to the IDE + typechecker. ↩
-
Guido at 1:30min
Guido van Rossum - python's type system explained
“Type annotations currently are not used for speeding up the interpreter, and there are a number of reasons. Many people don’t use them, even when they do use them they sometimes contain lies: where the static type checker says ‘everything is fine!’ […], but at runtime somehow, someone manages to violate that assumption.” ↩